Markerless Reconstruction of Dynamic Scenes
Christian Theobalt
Reconstruction of detailed animation models from multi-video data
Computer-generated people, so-called avatars, have become an important component of visual media, for example, in computer animations, films or networked virtual environments. In order to be able to present virtual humans in a convincing way, the individual characteristics of the person, such as, for example, his movement, geometry and surface texture, must be extremely realistically modeled. One way to achieve this is by defining every partial aspect of the overall appearance manually in an animation program. This is a very time intensive and complex process. The geometry of the person must be constructed in precise detail, and each nuance of movement must be finely specified. It is, therefore, easy to imagine that completely manually produced animations, especially with respect to the quality of movement animation, do not achieve the level of detail of a true human.
The alternative to manual modeling consists of measuring some aspects of animation from real people. Motion capture systems make it possible to reconstruct a skeletal model of a person using video image streams. Unfortunately, this method of movement capture is a very complex process, and the person being measured must often wear a special skin-tight suit with optical markers. In addition, neither the time changing geometry nor the texture of a person is captured with such systems.
In our research, we have developed a new type of Performance Capture Algorithms. For the first time, it is possible to reconstruct the detailed movement, dynamic geometry, and dynamic texture of a person in complex clothing, such as, a dress or a ball gown, solely from multi-video streams. Our process requires no optical markers in the scene.
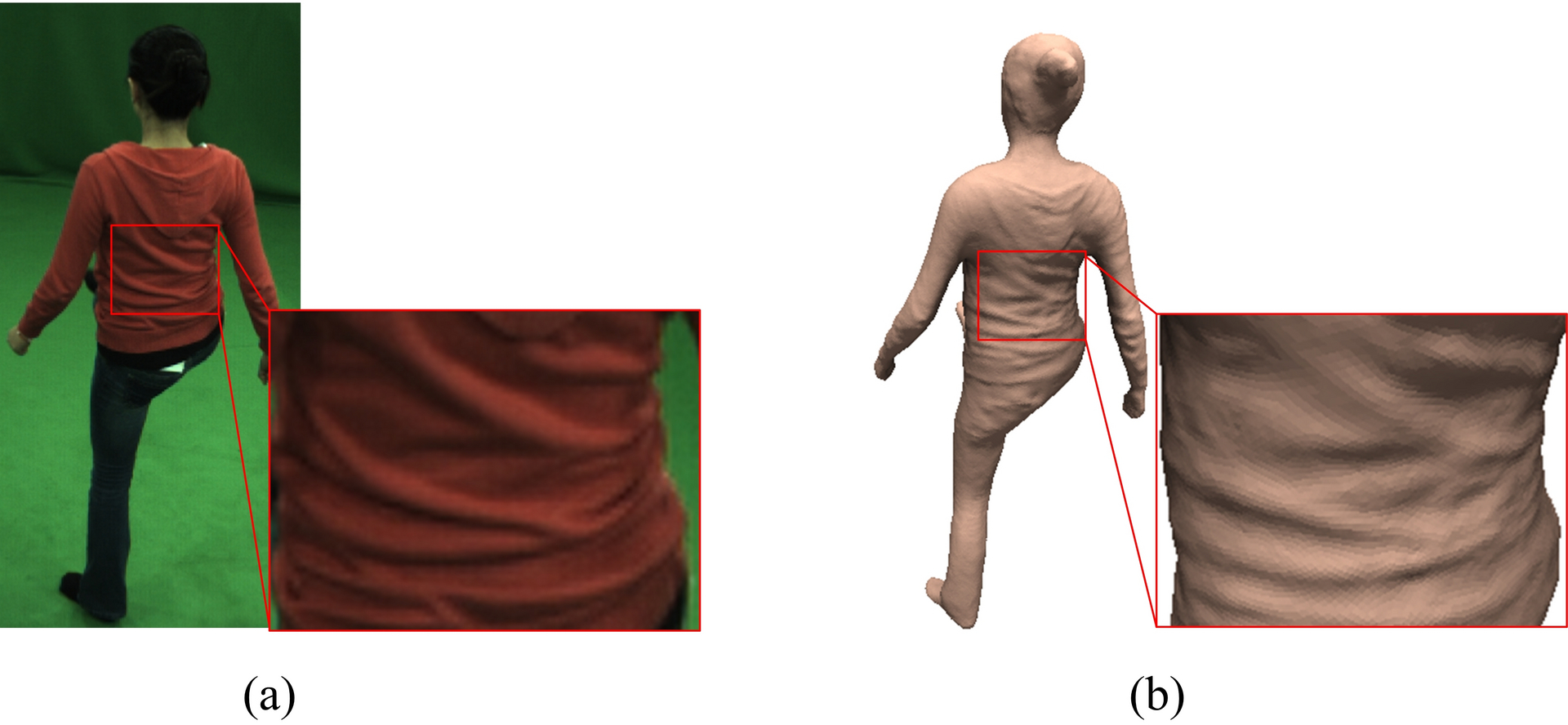
We have been able to improve our performance capture methods in many ways. A new algorithm enables us, for the first time, to reconstruct detailed animation models (i.e., surface+skeleton) of several closely interacting actors in the same scene [Figure 1]. A further milestone is a new algorithm to estimate incident illumination in arbitrary environments from multi-view video. Based on this estimated illumination model, one can reconstruct much more detailed dynamic surface geometry than with any previous approach from the literature available to date [Figure 1]. Based on these fundamentally new theories, we developed the first approach in the literature to reconstruct detailed animation models of human faces using a single stereo camera (see Figure 2). We also developed a new approach to capture much more accurate full body poses by exploiting lighting and reflectance models that we estimated from video footage of general scenes. Another important achievement is the development of a very fast motion estimation approach that can measure complex skeleton motion from multi-view video footage captured under less controlled environment conditions (i.e., no controlled background like in studio environments).
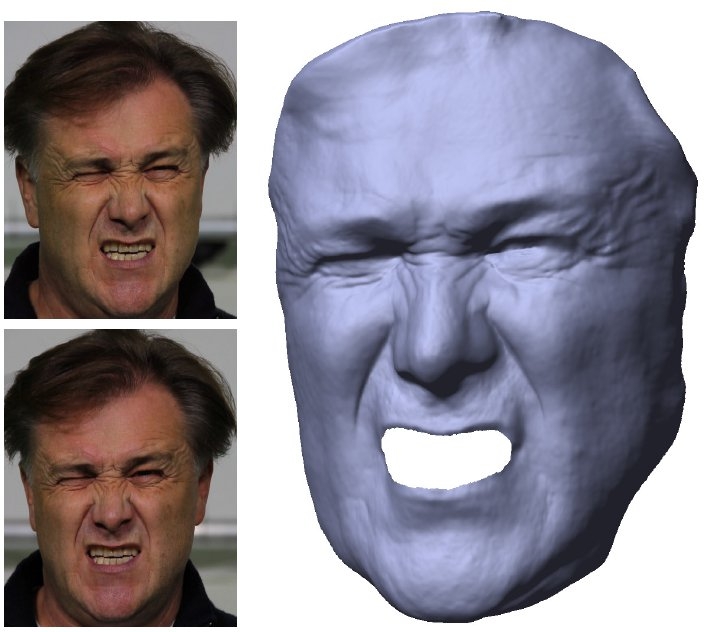
Figure2: We can reconstruct a highly detailed dynamic 3d model of the face (right) from the video frames of merely two cameras (left).
Real-time motion capture with depth sensors
The performance capture methods for exact detailed reconstruction, which were described in the previous section, require very complex calculations and are, therefore, not real-time. In addition, these methods require several video cameras. Motion measurement from a single camera perspective is an extremely complex and highly underconstrained problem.
New types of depth cameras, such as, for example, so-called Time-of-Flight cameras measure 2.5D scene geometry in real-time. It is easier to reconstruct body movements from a single camera perspective by using both depth and video data together. Unfortunately, depth camera data is very noisy, has low resolution and exhibits a systematic measurement bias. We have, therefore, developed methods to calibrate depth sensors, eliminate noise, and increase camera resolution through calculations on the original data (super-resolution process).
With improved depth data and through a newly-developed process from our research, all body movements of a person can be measured from one single camera perspective. The real time algorithm to measure movement combines a depth-based pose optimization procedure with a procedure for fast finding of similar poses from a large database of movement sequences.

About the author:
Christian Theobalt is a Professor of Compter Science and the head of the research group "Graphics, Vision, & Video" at the Max Planck Institute for Informatics. From 2007 until 2009 he was a Visiting Assistant Professor in the Department of Computer Science at Stanford University. He received his MSc degree in Artificial Intelligence from the University of Edinburgh, his Diplom (MS) degree in Computer Science from Saarland University, and his PhD in Computer Science from MPI Informatik.
Most of his research deals with algorithmic problems that lie on the boundary between the fields of Computer Vision and Computer Graphics, such as dynamic 3D scene reconstruction and marker-less motion capture, computer animation, appearance and reflectance modeling, machine learning for graphics and vision, new sensors for 3D acquisition, advanced video processing, as well as image- and physically-based rendering.
For his work, he received several awards including the Otto Hahn Medal of the Max Planck Society in 2007, the EUROGRAPHICS Young Researcher Award in 2009, and the German Pattern Recognition Award 2012. He is also a Principal Investigator and a member of the Steering Committee of the Intel Visual Computing Institute in Saarbrücken.
contact: theobalt (at) mpi-inf.mpg.de
www.mpi-inf.mpg.de/recouces/perfcap/